Anotações sobre SQL
1 Introdução a Bancos de Dados
Linguagem SQL ANSI - pequena diferença com MySQL
Mecanismos de armazenamento de dados. Conjunto de informação com estrutura regular.
• Bancos de dados não relacionais
– Arquivos estruturados
• Bancos de dados relacionais
– Dados organizados em tabelas
– Tabelas podem se relacionar com outras tabelas
– Menor espaço de armazenamento
– Maior velocidade de acesso aos dados
– Padrão mundialmente utilizado
Linhas=registros=tuplas
Visões - consultas SQL e dados das tabelas do banco sem armazená-los.
Índices - Estruturas que gerenciam a ordenação de valores dos campos informados para melhorar a performance de processamento destes campos.
SGBD
– Sistema Gerenciador de Banco de Dados - controlador de acesso
– DBMS: Database Management System
– SGBD não é um banco de dados, mas sim um complemento
– SGBD é um grupo de programas para interação com os dados
SQL (Structured Query Language)
– Linguagem Estruturada de Consulta
• Formada pelo conjunto das linguagens:
– DDL (Data Definition Language): Linguagem de Definição de Dados
– DML (Data Manipulation Language): Linguagem de Manipulação de Dados
– DQL (Data Query Language): Linguagem de Consulta de Dados
– DCL (Data Control Language): Linguagem de Controle de Dados - Gerenciar o acesso aos dados.
– DTL (Data Transaction Language): Linguagem de Transação de Dados - Gerenciar conjuntos de operações sobre os dados.
DDL
• CREATE: Cria uma estrutura
• ALTER: Altera uma estrutura
• DROP: Exclui uma estrutura
DML
• INSERT: Insere dados
• UPDATE: Altera dados
• DELETE: Exclui dados
DQL
• SELECT: Retorna dados: Ordenação de dados, Agrupamento de dados, Funções aritméticas, Filtros de seleção
DCL
• GRANT: Habilita acesso a dados e operações
• REVOKE: Revoga acesso a dados e operações
DTL
• START TRANSACTION: Inicia a transação
• COMMIT: Concretiza a transação
• ROLLBACK: Anula a transação
Principais bancos de dados
| MySQL | PostgreSQL | Firebird | Oracle | SQL Server | |
|---|---|---|---|---|---|
| SGBD | Sim | Sim | Sim | Sim | Sim |
| ACID | Sim | Sim | Sim | Sim | Sim |
| Licença Comercial | Não | Sim | Sim | Não | Não |
| Licença Estudante | Sim | Sim | Sim | Oracle Express | SQL Server Express |
2 Normalização de Dados
Relacionamentos e chaves
• Relacionamentos: Ligações entre tabelas.
• Chave Primária (Primary Key, PK): Coluna com valores únicos
• Chave Composta: Composição de duas ou mais colunas para gerar uma combinação única
• Chave Estrangeira (Foreign Key, FK): Coluna que armazena a chave primária de outra tabela
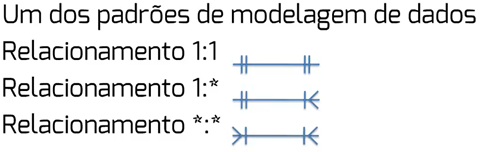
• Relacionamento 1 para 1 (1:1): Para cada registro da primeira tabela existe no máximo um correspondente na segunda tabela, e vice-versa.
• Relacionamento 1 para muitos (1:*): Para cada registro da primeira tabela pode existir um ou mais correspondentes na segunda tabela, e para cada registro na segunda tabela existe apenas um registro correspondente na primeira tabela.
• Relacionamento muitos para muitos (*:*): Para cada registro da primeira tabela pode existir um ou mais correspondentes na segunda tabela, e vice-versa.
Quanto menores as chaves (menos digitos), melhor. Maior transparência para o usuário.
Melhor usar códigos internos do sistema como chaves, e não dados exteriores ao sistema.
A normalização serve para: evitar anomalias; Facilitar a manutenção; Maximizar a performance; Manter a integridade dos dados;
Diagrama de modelo de dados
Anomalias dos dados
• Tabelas “fazem tudo” geram anomalias
• Anomalia de inserção: Impede a inclusão de registros devido à falta de dados
• Anomalia de exclusão: Impede a exclusão de registros devido ao relacionamento com outra tabela
• Anomalia de alteração: Impede a alteração de registros devido ao relacionamento com outra tabela
Normalização de dados
– 5 Formas Normais (FNs)
– Na prática a normalização é feita por intuição
– Resulta em um número maior de tabelas no banco
– Mais tabelas podem aumentar a manutenção e diminuir a performance
– Deve ser utilizado com bom senso
Primeira Forma Normal (1FN)
• Cada linha de tabela deve representar um registro
• Cada célula de tabela deve conter um único valor
Segunda Forma Normal (2FN)
• Obrigatoriamente estar na 1FN
• Atributos não chave da tabela devem depender de alguma das chaves da tabela
Terceira Forma Normal (3FN)
• Obrigatoriamente estar na 2FN
• Atributos não chave da tabela devem depender exclusivamente da chave primária da tabela
4FN e 5FN
• Separam em novas tabelas valores que ainda estejam redundantes em uma mesma coluna
3 Criando um Banco de Dados
SQL ANSI, ISO e outros
• SQL (Structured Query Language): Linguagem declarativa, detalha a forma do resultado Criado no início dos anos 70, em laboratórios da IBM novos dialetos surgiram, derivando e evoluindo o SQL
• Necessidade de padronização: American National Standards Institute (ANSI) em 1986; International Organization for Standardization (ISO) em 1987; Revisto pela primeira vez em 1992 originando o padrão SQL-92; Outras revisões: SQL:1999 incorporou características de expressões regulares, queries recursivas e triggers; SQL:2003 incorporou características de XML, sequências SQL:2008, SQL:2011.
Bancos de dados criam e evoluem suas próprias derivações do SQL. Curso aborda SQL padrão, com menções a outras derivações
Tipos de dados
Booleano e Numérico; String (char, onde o dado ocupará todo o espaço reservado, mesmo com espaços em branco, se necessário; e varchar, armazenando dados de tamanho variado sem espaços em branco desnecessários); Data e hora; Listas customizáveis (ENUM, não disponível em SQL Server ou Firebird).
BLOB: Permite o armazenamento de informações binárias, arquivos e imagens;
TEXT: Permite o armazenamento de grandes informações de strings;
Redes: Permite o armazenamento de endereços IP, MAC-ADDRESS e outros;
Monetários: Permite o armazenamento de valores monetários com formatação;
Geométricos: Permite o armazenamento de informações de formas geométricas;
Atributos
NULL / Not NULL: Permite ou não valores nulos;
Unsigned / Signed: Permite ou não números negativos;
Auto-increment: Sequências, contadores;
Zerofill: Preenche o valor numérico completando com zeros a esquerda;
Boas práticas de armazenamento
Espaço em disco: Quanto menor o tipo de dado, menos espaço ele ocupará;
Processamento e busca: Quanto menor o tipo de dado, mais rápido é o processamento;
Maus usos dos tipos de dados: Armazenar dados numéricos em colunas string; Armazenar dados numéricos em campos maiores que o necessário; Criar campos de string maiores do que o necessário;
Bom usos dos tipos de dados: Escolher o menor tipo de dados possível para armazenar suas informações; Pergunta: Qual o menor e maior valor que o campo poderá receber?
Criando um banco de dados
CREATE DATABASE Nome
Nomes sem espaços e sem caracteres especiais
Os conjuntos de caracteres mais utilizados são Latin1 e UTF-8 no Brasil
ALTER DATABASE Nome Propriedade
DROP DATABASE Nome
Exclusão é definitiva e irreversível
Tabela-Campos-Atributos
Criando uma tabela
CREATE TABLE Nome (Campos)
Sintaxe de descrição de campo: Nome TipoDeDado Atributos
Mais de um campo, separam-se com vírgulas
Atributos: Null, Zerofill, Unsigned, Auto-increment, Chave
ALTER TABLE Nome Propriedade
DROP TABLE Nome
Exclusão é definitiva e irreversível
Criando um índice
Índice: estrutura que armazena de forma isolada os registros de cada campo de forma ordenada.
• CREATE INDEX Nome ON TabelaEColuna
• ALTER INDEX Nome Propriedade
• DROP INDEX Nome
Criando uma sequência
Sequência: um campo de auto incremento.
• CREATE SEQUENCE Nome
• ALTER SEQUENCE Nome Propriedade
• DROP SEQUENCE Nome
Exclusão é definitiva e irreversível
Script de criação de banco de dados.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
create database curso_sql;
use curso_sql;
CREATE TABLE funcionarios (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
nome VARCHAR(45) NOT NULL,
salario DOUBLE NOT NULL DEFAULT '0',
departamento VARCHAR(45) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE veiculos (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
funcionario_id INT UNSIGNED DEFAULT NULL,
veiculo VARCHAR(45) NOT NULL DEFAULT '',
placa VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY (id),
CONSTRAINT fk_veiculos_funcionarios FOREIGN KEY (funcionario_id)
REFERENCES funcionarios (id)
);
CREATE TABLE salarios (
faixa VARCHAR(45) NOT NULL,
inicio DOUBLE NOT NULL,
fim DOUBLE NOT NULL,
PRIMARY KEY (faixa)
);
alter table funcionarios change column nome nome_func varchar(50) not null;
drop table salarios;
create index departamentos on funcionarios (departamento);
create index nomes on funcionarios (nome_func(6));
4 Manipulando Dados
Gerenciando dados
INSERT INTO Tabela VALUES (Valores)
SELECT Campos FROM Tabela
UPDATE Tabela SET Campo = Valor
DELETE FROM Tabela
· Filtros de seleção
WHERE
Não pode ser utilizado com o comando INSERT
Se o WHERE não for definido, o DELETE será aplicado a toda a tabela
• Operadores relacionais
– Igual (=), Diferente (!=)
– Maior (>), Maior ou igual (>=)
– Menor (<), Menor ou igual (<=)
– Nulo (IS NULL), ou não-nulo (IS NOT NULL)
– Entre intervalo (BETWEEN)
– Valor parcial (LIKE)
• Operadores lógicos
– AND
– OR
– NOT
set sql_safe_updates = 0; // desativa o safe updates, que impede alterações na tabela toda// valor 1 reativa.
Consultando dados com filtros
SELECT Campos FROM Tabela WHERE Condição
UPDATE Tabela SET Campo = Valor ROUND(valor/operação, número de casas) WHERE Condição
DELETE FROM Tabela WHERE Condição
Atributos especiais
• Apelido de tabela
SELECT Campos FROM Tabela Apelido …
• Apelido de campos (AS)
SELECT Campo AS Apelido FROM …
• Unindo seleções (UNION [ALL])
SELECT … UNION SELECT …
Manipulando dados.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
use curso_sql;
insert into funcionarios (id, nome_func, salario, departamento) values (1, 'Fernando', 1400, 'TI');
insert into funcionarios (nome_func, salario, departamento) values ('José', 1800, 'Marketing');
insert into funcionarios (nome_func, salario, departamento) values ('Isabela', 2200, 'Jurídico');
select * from funcionarios;
select * from funcionarios where salario > 2000;
update funcionarios set salario = salario * 1.1 where id = 1;
set sql_safe_updates = 0;
update funcionarios set salario = round(salario * 1.1, 2);
set sql_safe_updates = 1;
delete from funcionarios where id = 4;
select nome_func, salario from funcionarios f where f.salario > 2000;
select nome_func as 'nome do funcionario', salario from funcionarios f where f.salario > 2000;
select nome_func, salario from funcionarios f where f.salario > 2000
union
select nome_func as 'nome do funcionario', salario from funcionarios f where f.salario > 2000;
5 Relacionamentos e Visões
Relacionamentos no SQL
• Informações relacionadas entre si
• Em geral entre diferentes tabelas
• Geralmente possuem campos em comum
• Parâmetro JOIN e suas variações
• SELECT … FROM T1 JOIN T2 ON T1.FK = T2.PK
• SELECT … FROM T1 JOIN T2 USING Chave (Equi join)
• Compatibilidade com bancos de dados
Inner join
• Join padrão
• Produto cartesiano entre as tabelas
• Combina todas as linhas da primeira tabela com todas as linhas da segunda, que satisfaçam as condições das chaves
Equi join
• Similar ao Inner join
• Chaves de mesmo nome entre as tabelas - Não irão se repetir na tabela de resultados
Non equi join
• Relacionamento sem um campo em comum
• SELECT P.NOME, P.SALARIO, S.FAIXA FROM PESSOAS P INNER JOIN SALARIOS S ON P.SALARIO BETWEEN S.INICIO AND S.FIM
Outer join, Left join, Left outer join
• Linhas que não satisfazem a condição de união
• Left: Linhas da primeira tabela cujo campo de condição não satisfaçam a união de tabelas
• SELECT * FROM PESSOAS LEFT JOIN VEICULOS ON PESSOAS.CPF = VEICULOS.CPF
Right join, Right outer join
• Similar ao Left join
• Right: Linhas da segunda tabela cujo campo de condição não satisfaçam a união de tabelas
• SELECT * FROM PESSOAS RIGHT JOIN VEICULOS ON PESSOAS.CPF = VEICULOS.CPF
Full outer join
• Combinação de Left join e Right join
• Linhas da primeira e segunda tabela cujos campos de condição não satisfaçam a união de tabelas
• SELECT * FROM PESSOAS FULL JOIN VEICULOS ON PESSOAS.CPF =VEICULOS.CPF
No MySQL utiliza o UNION com LEFT e RIGHT
Self join
• União da tabela com ela mesma
• SELECT A.NOME, B.NOME AS INDICADO_POR FROM PESSOAS A JOIN PESSOAS B ON A.INDICADO = B.CPF
Visões
São comandos SELECT pré-programados para ficarem disponíveis no banco de dados.
É possível construir visões de relacionamento entre tabelas (JOINS).
Não armazenam dados.
• Relação que não faz parte do modelo lógico
• Acessível ao usuário como uma relação virtual
• Otimização de espaço em disco
• Centralização de código
• Facilidade de manutenção de expressões SQL
Criando uma visão
• CREATE VIEW Nome AS ExpressãoSQL
• ALTER VIEW Nome Propriedade Exclusão e nova criação (substituição)
• DROP VIEW Nome // Apenas a estrutura da visão é removido. Os dados permanecem intactos em suas respectivas tabelas
Relacionamentos e visões.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
USE curso_sql;
SELECT * FROM funcionarios;
SELECT * FROM veiculos;
SELECT * FROM funcionarios INNER JOIN veiculos ON veiculos.funcionario_id = funcionarios.id;
SELECT * FROM funcionarios f INNER JOIN veiculos v ON v.funcionario_id = f.id;
SELECT * FROM funcionarios f LEFT JOIN veiculos v ON v.funcionario_id = f.id;
SELECT * FROM funcionarios f RIGHT JOIN veiculos v ON v.funcionario_id = f.id;
SELECT * FROM funcionarios f LEFT JOIN veiculos v ON v.funcionario_id = f.id
UNION
SELECT * FROM funcionarios f RIGHT JOIN veiculos v ON v.funcionario_id = f.id;
INSERT INTO veiculos (funcionario_id, veiculo, placa) VALUES (null, "Moto", "SB-0003");
CREATE TABLE cpfs
(
id int unsigned not null,
cpf varchar(14) not null,
PRIMARY KEY (id),
CONSTRAINT fk_cpf FOREIGN KEY (id) REFERENCES funcionarios (id)
);
INSERT INTO cpfs (id, cpf) VALUES (1, '111.111.111-11');
INSERT INTO cpfs (id, cpf) VALUES (2, '222.222.222-22');
INSERT INTO cpfs (id, cpf) VALUES (3, '333.333.333-33');
INSERT INTO cpfs (id, cpf) VALUES (5, '555.555.555-55');
SELECT * FROM cpfs;
SELECT * FROM funcionarios INNER JOIN cpfs ON funcionarios.id = cpfs.id;
SELECT * FROM funcionarios INNER JOIN cpfs USING(id);
CREATE TABLE clientes
(
id int unsigned not null auto_increment,
nome varchar(45) not null,
quem_indicou int unsigned,
PRIMARY KEY (id),
CONSTRAINT fk_quem_indicou FOREIGN KEY (quem_indicou) REFERENCES clientes (id)
);
INSERT INTO clientes (id, nome, quem_indicou) VALUES (1, 'André', NULL);
INSERT INTO clientes (id, nome, quem_indicou) VALUES (2, 'Samuel', 1);
INSERT INTO clientes (id, nome, quem_indicou) VALUES (3, 'Carlos', 2);
INSERT INTO clientes (id, nome, quem_indicou) VALUES (4, 'Rafael', 1);
SELECT * FROM clientes;
SELECT a.nome AS CLIENTE, b.nome AS "QUEM INDICOU"
FROM clientes a join clientes b ON a.quem_indicou = b.id;
SELECT * FROM funcionarios
INNER JOIN veiculos ON veiculos.funcionario_id = funcionarios.id
INNER JOIN cpfs ON cpfs.id = funcionarios.id;
CREATE VIEW funcionarios_a AS SELECT * FROM funcionarios WHERE salario >= 1700;
SELECT * FROM funcionarios_a;
UPDATE funcionarios SET salario = 1500 WHERE id = 3;
DROP VIEW funcionarios_a;
CREATE VIEW funcionarios_a AS SELECT * FROM funcionarios WHERE salario >= 2000;
6 Funções Especiais e Subqueries
Funções de agregação
– COUNT: Contagem de registros de uma consulta SELECT COUNT() FROM
– SUM: Soma de valores SELECT SUM() FROM
– AVG: Média de valores SELECT AVG() FROM
– MAX: Valor máximo retornado pela consulta SELECT MAX() FROM
– MIN: Valor mínimo retornado pela consulta SELECT MIN() FROM
É possível integrar com WHERE com uma condição
Funções de paginação
– DISTINCT: Seleciona os valores únicos, sem repetição
– ORDER BY: Ordena o resultado baseado nas colunas informadas – DESC / ASC
– LIMIT: Limita o número de resultados retornados
– OFFSET: Indica quantos registros devem ser avançados
• Combinações são permitidas
Funções de agrupamento
– GROUP BY: Agrupamento de registros por categoria
– HAVING: Seleção de agrupamento
Subqueries
• Realização de consultas com filtro de seleção baseado em uma lista ou outra seleção
• IN / NOT IN
SELECT NOME FROM FUNCIONARIOS WHERE DEPARTAMENTO IN (‘Marketing’, ‘TI’)
Funções Especiais e Subqueries.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
USE curso_sql;
SELECT * FROM funcionarios;
SELECT COUNT(*) FROM funcionarios;
SELECT COUNT(*) FROM funcionarios WHERE salario > 1600;
SELECT COUNT(*) FROM funcionarios WHERE salario > 1600 AND departamento = 'Jurídico';
SELECT * FROM funcionarios WHERE salario > 1600 AND departamento = 'Jurídico';
SELECT SUM(salario) FROM funcionarios;
SELECT SUM(salario) FROM funcionarios WHERE departamento = 'TI';
SELECT AVG(salario) FROM funcionarios;
SELECT AVG(salario) FROM funcionarios WHERE departamento = 'TI';
SELECT MAX(salario) FROM funcionarios;
SELECT MAX(salario) FROM funcionarios WHERE departamento = 'TI';
SELECT MIN(salario) FROM funcionarios;
SELECT MIN(salario) FROM funcionarios WHERE departamento = 'TI';
SELECT departamento FROM funcionarios;
SELECT DISTINCT(departamento) FROM funcionarios;
SELECT * FROM funcionarios;
SELECT * FROM funcionarios ORDER BY nome;
SELECT * FROM funcionarios ORDER BY nome DESC;
SELECT * FROM funcionarios ORDER BY salario;
SELECT * FROM funcionarios ORDER BY departamento;
SELECT * FROM funcionarios ORDER BY departamento DESC, salario DESC;
SELECT * FROM funcionarios;
SELECT * FROM funcionarios LIMIT 2 OFFSET 1;
SELECT * FROM funcionarios LIMIT 1, 2;
SELECT AVG(salario) FROM funcionarios;
SELECT AVG(salario) FROM funcionarios WHERE departamento = 'TI';
SELECT AVG(salario) FROM funcionarios WHERE departamento = 'Jurídico';
SELECT departamento, AVG(salario) FROM funcionarios GROUP BY departamento;
SELECT departamento, AVG(salario) FROM funcionarios GROUP BY departamento HAVING AVG(salario) > 2000;
SELECT departamento, COUNT(*) FROM funcionarios GROUP BY departamento;
SELECT departamento, AVG(salario) FROM funcionarios GROUP BY departamento;
SELECT nome FROM funcionarios WHERE departamento = 'Jurídico';
SELECT nome FROM funcionarios
WHERE departamento IN
(
SELECT departamento FROM funcionarios GROUP BY departamento HAVING AVG(salario) > 2000
);
SELECT departamento, AVG(salario) FROM funcionarios GROUP BY departamento HAVING AVG(salario) > 2000;
7 Controle de Acesso
DCL - Controle de acesso
• Forma de garantir que somente pessoas autorizadas possam realizar ações com os dados
• Níveis de acesso
– Banco de dados
– Tabelas
– Colunas
– Registros
• Níveis de ações
– Gerenciar estruturas
– Gerenciar dados
– Ler dados
• Linguagem de Controle de Dados
– CREATE USER ‘Nome’@’local/ip/localhost/% qualquer endereço’ IDENTIFIED BY ‘senha’: Cria um usuário
– DROP USER Nome: Exclui um usuário
– GRANT: Habilita acessos
– REVOKE: Revoga acessos
• Habilitando acesso
GRANT Ação ON Estrutura TO ‘Usuário’
• Revogando acesso
REVOKE Ação ON Estrutura FROM Usuário
• Ações
ALL, SELECT, INSERT, UPDATE, DELETE
• Estruturas
TABLE, VIEW, SEQUENCE
Controle de Acesso.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/* CREATE USER 'andre'@'200.200.190.190' IDENTIFIED BY 'milani123456'; */
/* CREATE USER 'andre'@'%' IDENTIFIED BY 'milani123456'; */
CREATE USER 'andre'@'localhost' IDENTIFIED BY 'milani123456';
GRANT ALL ON curso_sql.* TO 'andre'@'localhost';
CREATE USER 'andre'@'%' IDENTIFIED BY 'andreviagem';
GRANT SELECT ON curso_sql.* TO 'andre'@'%';
/* GRANT INSERT ON curso_sql.* TO 'andre'@'%'; */
GRANT INSERT ON curso_sql.funcionarios TO 'andre'@'%';
REVOKE INSERT ON curso_sql.funcionarios FROM 'andre'@'%';
REVOKE SELECT ON curso_sql.* FROM 'andre'@'%';
GRANT SELECT ON curso_sql.funcionarios TO 'andre'@'%';
GRANT SELECT ON curso_sql.veiculos TO 'andre'@'%';
REVOKE SELECT ON curso_sql.funcionarios FROM 'andre'@'%';
REVOKE SELECT ON curso_sql.veiculos FROM 'andre'@'%';
REVOKE ALL ON curso_sql.* FROM 'andre'@'localhost';
DROP USER 'andre'@'%';
DROP USER 'andre'@'localhost';
SELECT User FROM mysql.user;
SHOW GRANTS FOR 'andre'@'%';
8 Transações (ACID)
Transações (ACID)
• Conjunto de operações
• ACID
– Atomicidade: ou transação é realizada por completo ou nada é realizado;
– Consistência: regras não podem ser quebradas;
– Isolamento: os dados são travados até o fim da transação;
– Durabilidade: após o sucesso da transação os dados, as operações ficam novamente disponíveis.
Data Transaction Language (DTL)
• Linguagem de Transação de Dados
– START TRANSACTION: Inicia a transação
– COMMIT: Concretiza a transação
– ROLLBACK: Anula a transação
Transações.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
USE curso_sql;
SHOW ENGINES;
CREATE TABLE contas_bancarias
(
id int unsigned not null auto_increment,
titular varchar(45) not null,
saldo double not null,
PRIMARY KEY (id)
) engine = InnoDB;
INSERT INTO contas_bancarias (titular, saldo) VALUES ('André', 1000);
INSERT INTO contas_bancarias (titular, saldo) VALUES ('Carlos', 2000);
SELECT * FROM contas_bancarias;
start transaction;
UPDATE contas_bancarias SET saldo = saldo - 100 WHERE id = 1;
UPDATE contas_bancarias SET saldo = saldo + 100 WHERE id = 2;
rollback;
start transaction;
UPDATE contas_bancarias SET saldo = saldo - 100 WHERE id = 1;
UPDATE contas_bancarias SET saldo = saldo + 100 WHERE id = 2;
commit;
9 Stored Procedures e Triggers
Stored Procedures
• Blocos de código SQL armazenados no banco
• Vantagens
– Centralização
– Segurança
– Performance / velocidade
– Suporte a transações
• Criando uma Stored Procedure:
CREATE PROCEDURE Nome
• Invocando uma Stored Procedure:
CALL Nome
EXECUTE Nome
• Excluindo uma Stored Procedure:
DROP PROCEDURE Nome
Triggers (Gatilhos)
• Eventos que disparam códigos SQL
• Vantagens
– As mesmas das Stored Procedures
– Execução de código SQL baseado em eventos
• Tipos
– BEFORE INSERT
– BEFORE UPDATE
– BEFORE DELETE
– AFTER INSERT
– AFTER UPDATE
– AFTER DELETE
– TEMPORAIS
• Criando um Trigger:
CREATE TRIGGER Nome Tipo ON tabela
• Excluindo uma Trigger:
DROP TRIGGER Nome
Stored Procedures e Triggers.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
USE curso_sql;
CREATE TABLE pedidos
(
id int unsigned not null auto_increment,
descricao varchar(100) not null,
valor double not null default '0',
pago varchar(3) not null default 'Não',
PRIMARY KEY (id)
);
INSERT INTO pedidos (descricao, valor) VALUES ('TV', 3000);
INSERT INTO pedidos (descricao, valor) VALUES ('Geladeira', 1400);
INSERT INTO pedidos (descricao, valor) VALUES ('DVD Player', 300);
/*
Criar Stored Procedures pelo menu lateral, com este SQL:
SET SQL_SAFE_UPDATES = 0;
DELETE FROM pedidos WHERE pago = 'Não';
*/
SELECT * FROM pedidos;
CALL limpa_pedidos();
CREATE TABLE estoque
(
id int unsigned not null auto_increment,
descricao varchar(50) not null,
quantidade int not null,
PRIMARY KEY (id)
);
CREATE TRIGGER gatilho_limpa_pedidos
BEFORE INSERT
ON estoque
FOR EACH ROW
CALL limpa_pedidos();
SELECT * FROM pedidos;
INSERT INTO pedidos (descricao, valor) VALUES ('TV', 3000);
INSERT INTO pedidos (descricao, valor) VALUES ('Geladeira', 1400);
INSERT INTO pedidos (descricao, valor) VALUES ('DVD Player', 300);
SELECT * FROM pedidos;
UPDATE pedidos SET pago = 'Sim' WHERE id = 8;
SELECT * FROM pedidos;
INSERT INTO estoque (descricao, quantidade) VALUES ('Fogão', 5);
SELECT * FROM pedidos;
SELECT * FROM estoque;
INSERT INTO estoque (descricao, quantidade) VALUES ('Forno', 3);
SELECT * FROM pedidos;
SELECT * FROM estoque;